One of the goals of The 100,000 Genomes Project from Genomics England is to enable new medical research. Researchers will study how best to use genomics in healthcare and how best to interpret the data to help patients. The causes, diagnosis and treatment of disease will also be investigated. This is currently the largest national sequencing project of its kind in the world.
To achieve this goal Genomics England set up a Research environment for researchers and clinicians. OpenCGA, CellBase and IVA from OpenCB were installed as data platform. We loaded 64,078 whole genomes in OpenCGA, in total more than 1 billion unique variants were indexed in the OpenCGA Variant Storage, and all the metadata and clinical data for samples and patients were loaded in OpenCGA Catalog. OpenCGA was able to index about 6,000 samples a day, variant annotation and cohort stats for the all the data run in less than a week. All data was loaded, annotated and stats calculated in less than 2 weeks. Genomics variants were annotated using CellBase and the IVA front-end was installed to analyse and visualise the data. In this case study you can find a full report of about the loading and analysis of the 64,078 genomes.
Genomic and Clinical Data
Clinical data and genomic variants of 64,078 genomes were loaded and indexed in OpenCGA. In total we loaded more than 30,000 VCF compressed files accounting for about 40TB of disk space. Data was divided in four different datasets depending on the genome assembly (GRCh37 or GRCh38) and the type of study (germline or somatic), this data has been organised in OpenCGA in three different Projects and four Studies:
| Project | Study ID and Name | Samples | VCF Files | VCF File Type | Samples/File | Variants |
|---|---|---|---|---|---|---|
| GRCh37 Germline | RD37 Rare Disease GRCh37 | 12,142 | 5,329 | Multi sample | 2.28 | 298,763,059 |
| GRCh38 Germline | RD38 Rare Disease GRCh38 | 33,180 | 16,591 | Multi sample | 2.00 | 437,740,498 |
CG38 Cancer Germline GRCh38 | 9,167 | 9,167 | Single sample | 1.00 | 286,136,051 | |
| GRCh38 Somatic | CS38 Cancer Somatic GRCh38 | 9,589 | 9,589 | Somatic | 1.00 | 398,402,166 |
| Total | 64,078 | 40,676 | 1,421,041,774 | |||
OpenCGA Catalog stores all the metadata and clinical data of files, samples, individuals and cohorts. Rare Disease studies also include pedigree metadata by defining families. Also, a Clinical Analysis were defined for each family. Several Variable Sets have been defined to store GEL custom data for all these entities.
Platform
For the Research environment we have used OpenCGA v1.4 using the new Hadoop Variant Storage that use Apache HBase as back-end because of the huge amount of data and analysis needed. We have also used CellBase v4.6 for the variant annotation. Finally we set up a IVA v1.0 web-based variant analysis tool.
The Hadoop cluster consists of about 30 nodes running Hortonworks HDP 2.6.5 (which comes with HBase 1.1.2) and a LSF queue for loading all the VCF files, see this table for more detail:
| Node | Nodes | Cores | Memory (GB) | Storage (TB) |
|---|---|---|---|---|
| Hadoop Master | 5 | 28 | 216 | 7.2 (6x1.2) |
| Hadoop Worker | 30 | 28 | 216 | 7.2 (6x1.2) |
| LSF Loading Queue | 10 | 12 | 364 | Isilon storage |
Genomic Data Load
In order to improve the loading performance, we set up a small LSF queue of ten computing nodes. This configuration allowed us to load multiple files at the same time. We configured LSF to load up to 6 VCF files per node resulting in 60 files being loaded in HBase in parallel without any incidence, by doing this we observed a 50x in loading throughput. This resulted in an average of 125 VCF files loaded per hour in studies RD37 and RD38, which is about 2 files per minute. In the study CG38 the performance was 240 VCF files per hour or about 4 files per minute.
Rare Disease Loading Performance
The files from Rare Disease studies (RD38 & RD37) contain 2 samples per file on average. This results in larger files, increasing the loading time compared with single-sample files. As mentioned above the loading performance was about 125 files per hour or 3,000 files per day. In terms of number of samples it is about 250 samples per hour or 6,000 samples a day.
The loading performance always depend on the number of variants and concurrent files being loaded, the performance was quite stable during the load and performance degradation was observed as can be seen here:
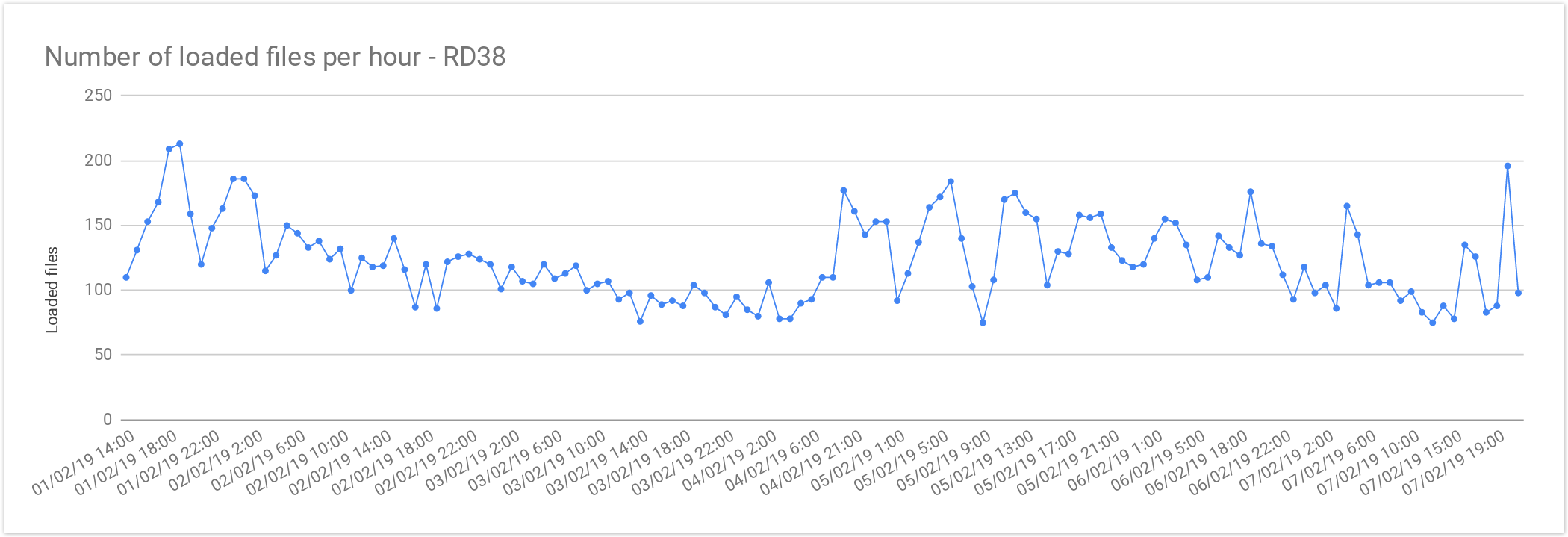
| Concurrent files loaded | 60 |
|---|---|
| Average files loaded per hour | 125.72 |
| Load time per file | 00:28:38 |
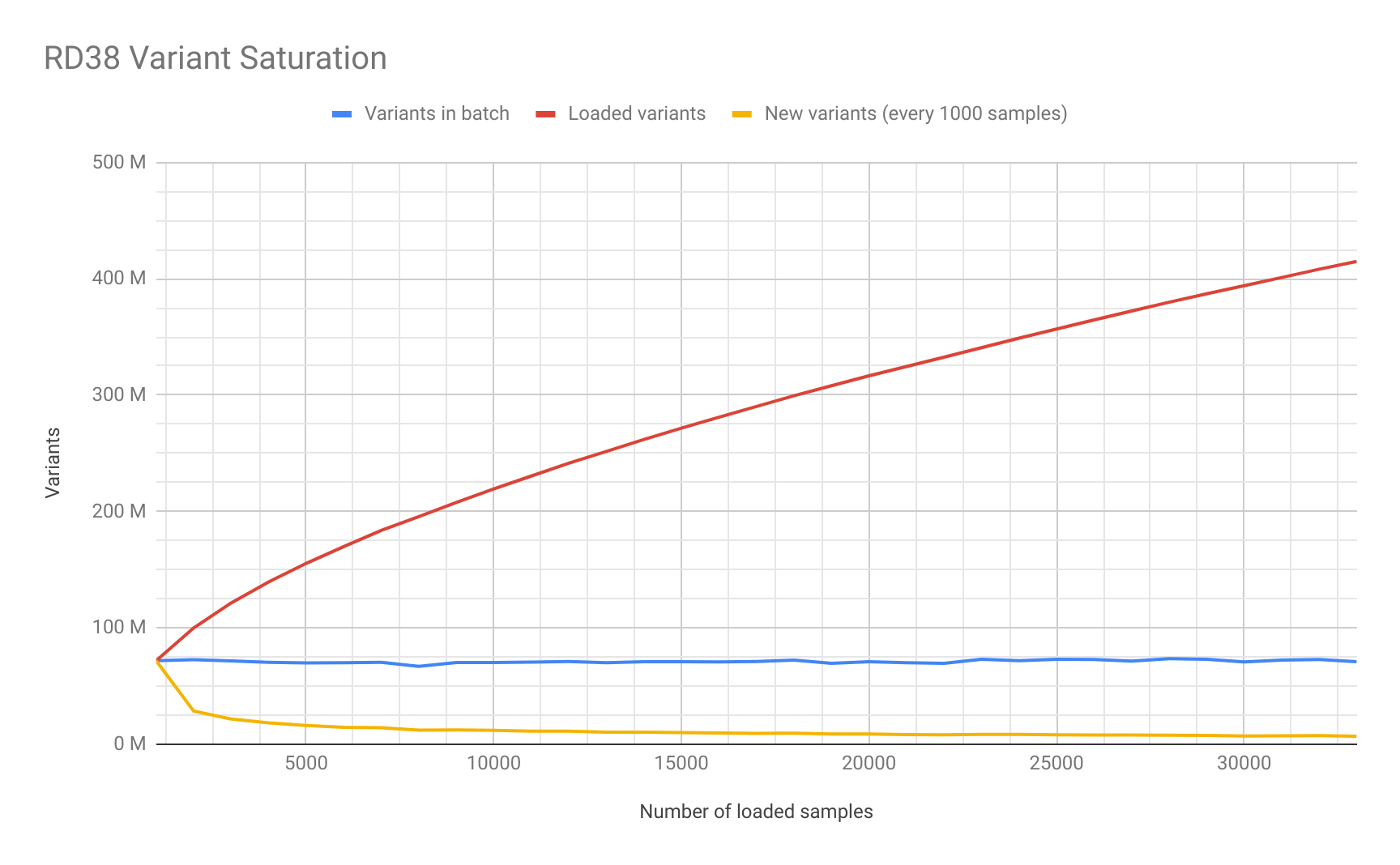
Saturation Study
As part of the data loading process we decided to study the number of unique variants added in each batch of 500 samples. We generated this saturation plot for RD38:
Cancer Loading Performance
The files from Cancer Germline studies (CG38) contain one sample per file. Compared with the Rare Disease, these files are smaller in size, therefore, as expected the file load was almost 2x faster. As mentioned above, the loading performance was about 240 genomes per hour or 5,800 files per day. In terms of number of samples it is about 5,800 samples a day, which is consistent with Rare Disease performance.
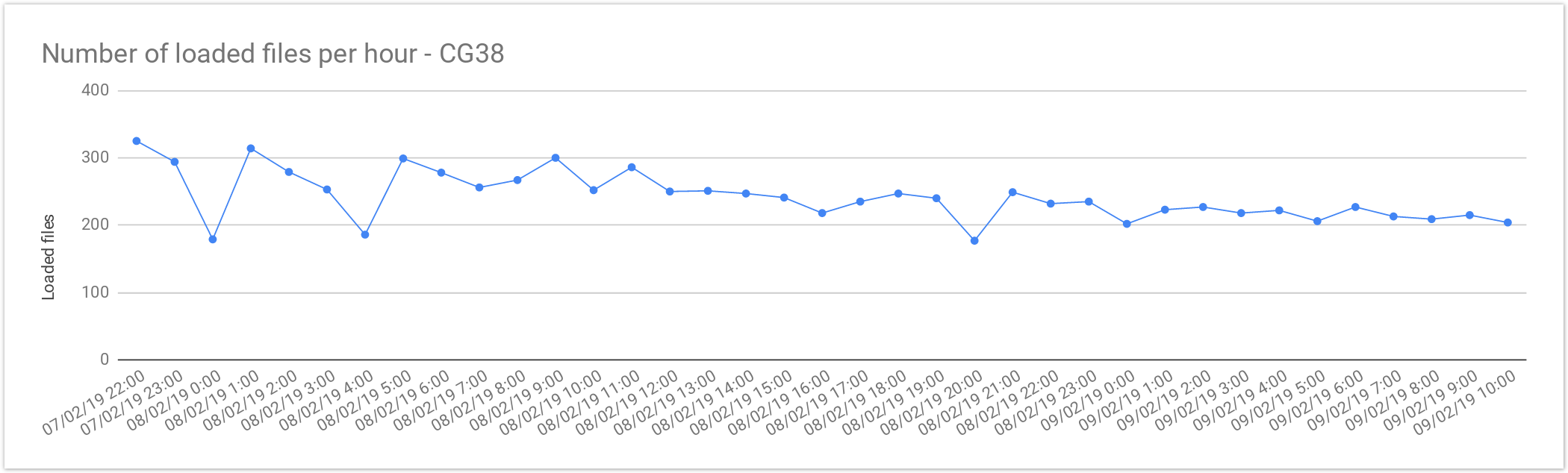
| Concurrent files loaded | 60 |
|---|---|
| Average files loaded per hour | 242.05 |
| Load time per file | 00:14:52 |
Analysis Benchmark
In this section you can find information about the performance of main variant storage operations and most common queries and clinical analysis. Please, for data loading performance information go to section Genomic Data Load above.
Variant Storage Operations
Variant Storage operations take care of preparing the data for executing queries and analysis. There are two main operations: Variant Annotation and Cohort Stats Calculation.
Variant Annotation
This operation uses the CellBase to annotate each unique variant in the database, this annotation include consequence types, population frequencies, conservation scores clinical info, ... and will be typically used for variant queries and clinical analysis. Variant annotation of the 585 million unique variants of project GRCh38 Germline took about 3 days, about 200 million variants were annotated per day.
Cohort Stats Calculation
Cohort Stats are used for filtering variants in a similar way as the population frequencies. A set of cohorts were defined in each study.
- ALL with all samples in the study
- PARENTS with all parents in the study (only for Rare Disease studies)
- UNAFF_PARENTS with all unaffected parents in the study (only for Rare Disease studies)
Pre-computing stats for different cohort and ten of thousands of samples is a high-performance operation that run in less than 2 hours for each study.
Query and Aggregation Stats
To study the performance we used RD38 which the largest study with 438 million variants and 33,000 samples. We first run some queries to the aggregated data filtering by variant annotation and cohort stats. We were interested in the different index performance so we limit the results to the first 10 variants, very similar results are obtained with a bigger limit.
| Filter | Results | Total Results | Time |
|---|---|---|---|
| consequence type = LoF + missense_variant | 10 | 3704626 | 0.189s |
consequence type = LoF + missense_variant biotype = protein_coding | 10 | 3576472 | 0.260s |
panel = with 200 genes | 10 | 3882902 | 0.299s |
Clinical Analysis
Clinical queries, or sample queries, enforces queries to return variants of a specific set of samples. These queries can use all the filters from the general queries. The result will include a ReportedEvent for each variant, which determines possible conditions associated to the variant.
| Filter | Results | Total Results | Time |
|---|---|---|---|
mode of inheritance = recessive filter = PASS | 10 | 211787 | 0.420s |
mode of inheritance = recessive filter = PASS | 2000 | 211787 | 1.079s |
de novo Analysis filter = PASS consequence type = LoF + missense_variant | 24 | 24 | 0.680s |
| Compound Heterozygous Analysis filter = PASS biotype = protein_coding consequence type = LoF + missense_variant | 417 | 417 | 10.930s |
User Interfaces
Several user interfaces have been developed to query and analyse data from OpenCGA: IVA web-based tool, Python and R clients, and a command line.
IVA
IVA v1.0.3 was installed to provide a friendly web-based analysis tool to browse variants and execute clinical analysis.
Command line
You can also query variants efficiently using the command line built in. Performance depends on the number of samples fetched and the RPC used (REST or gRPC), in the best scenario you can fetch few thousands variants per second. You can see a simple example here.
| Code Block | ||||
|---|---|---|---|---|
| ||||
imedina@ivory:~/appl/opencga/build[develop]$ ./bin/opencga.sh variant query --gene BRCA2 --include-sample none --limit 10 --study RD37 ##fileformat=VCFv4.2 ##FILTER=<ID=.,Description="No FILTER info"> ##FILTER=<ID=GOF,Description="Variant fails goodness-of-fit test."> ##FILTER=<ID=HapScore,Description="Too many haplotypes are supported by the data in this region."> ##FILTER=<ID=MQ,Description="Root-mean-square mapping quality across calling region is low."> ##FILTER=<ID=PASS,Description="All filters passed"> ##FILTER=<ID=Q20,Description="Variant quality is below 20."> ##FILTER=<ID=QD,Description="Variants fail quality/depth filter."> ##FILTER=<ID=QualDepth,Description="Variant quality/Read depth ratio is low."> ##FILTER=<ID=REFCALL,Description="This line represents a homozygous reference call"> ##FILTER=<ID=SC,Description="Variants fail sequence-context filter. Surrounding sequence is low-complexity"> ##FILTER=<ID=alleleBias,Description="Variant frequency is lower than expected for het"> ##FILTER=<ID=badReads,Description="Variant supported only by reads with low quality bases close to variant position, and not present on both strands."> ##FILTER=<ID=hp10,Description="Flanking sequence contains homopolymer of length 10 or greater"> ##FILTER=<ID=strandBias,Description="Variant fails strand-bias filter"> ##FORMAT=<ID=GL,Number=.,Type=Float,Description="Genotype log10-likelihoods for AA,AB and BB genotypes, where A = ref and B = variant. Only applicable for bi-allelic sites"> ##FORMAT=<ID=GOF,Number=.,Type=Float,Description="Goodness of fit value"> ##FORMAT=<ID=GQ,Number=1,Type=Integer,Description="Genotype Quality"> ##FORMAT=<ID=GT,Number=1,Type=String,Description="Unphased genotypes"> ##FORMAT=<ID=NR,Number=A,Type=Integer,Description="Number of reads covering variant location in this sample"> ##FORMAT=<ID=NV,Number=A,Type=Integer,Description="Number of reads containing variant in this sample"> ##FORMAT=<ID=PL,Number=G,Type=Integer,Description="Normalized, Phred-scaled likelihoods for genotypes as defined in the VCF specification"> ##FORMAT=<ID=PS,Number=1,Type=Integer,Description="ID for set of phased genotypes"> ##INFO=<ID=AC,Number=A,Type=Integer,Description="Total number of alternate alleles in called genotypeCounters, for each ALT allele, in the same order as listed"> ##INFO=<ID=AF,Number=A,Type=Float,Description="Allele Frequency, for each ALT allele, calculated from AC and AN, in the range (0,1), in the same order as listed"> ##INFO=<ID=AN,Number=1,Type=Integer,Description="Total number of alleles in called genotypeCounters"> ##INFO=<ID=BRF,Number=1,Type=Float,Description="Fraction of reads around this variant that failed filters"> ##INFO=<ID=CT,Number=1,Type=String,Description="Consequence annotations (separated by &) from CellBase. Format: gene"> ##INFO=<ID=END,Number=1,Type=Integer,Description="Stop position of the interval"> ##INFO=<ID=FR,Number=A,Type=Float,Description="Estimated population frequency of variant"> ##INFO=<ID=FS,Number=.,Type=Float,Description="Fisher's exact test for strand bias (Phred scale)"> ##INFO=<ID=HP,Number=1,Type=Integer,Description="Homopolymer run length around variant locus"> ##INFO=<ID=HapScore,Number=.,Type=Integer,Description="Haplotype score measuring the number of haplotypes the variant is segregating into in a window"> ##INFO=<ID=MGOF,Number=.,Type=Integer,Description="Worst goodness-of-fit value reported across all samples"> ##INFO=<ID=MMLQ,Number=1,Type=Float,Description="Median minimum base quality for bases around variant"> ##INFO=<ID=MQ,Number=1,Type=Float,Description="RMS Mapping Quality"> ##INFO=<ID=NF,Number=A,Type=Integer,Description="Total number of forward reads containing this variant"> ##INFO=<ID=NR,Number=A,Type=Integer,Description="Total number of reverse reads containing this variant"> ##INFO=<ID=OLD_CLUMPED,Number=1,Type=String,Description="Original chr:pos:ref:alt encoding"> ##INFO=<ID=OLD_MULTIALLELIC,Number=1,Type=String,Description="Original chr:pos:ref:alt encoding"> ##INFO=<ID=OLD_VARIANT,Number=.,Type=String,Description="Original chr:pos:ref:alt encoding"> ##INFO=<ID=PARENTS_AF,Number=A,Type=Float,Description="Allele frequency in the PARENTS cohort calculated from AC and AN, in the range (0,1), in the same order as listed"> ##INFO=<ID=POPFREQ,Number=1,Type=String,Description="Alternate allele frequencies for study and population (separated by |), e.g.: 1kG_phase3_IBS:0.06542056|1kG_phase3_CEU:0.08585858"> ##INFO=<ID=PP,Number=A,Type=Float,Description="Posterior probability (phred scaled) that this variant segregates"> ##INFO=<ID=QD,Number=1,Type=Float,Description="Variant-quality/read-depth for this variant"> ##INFO=<ID=ReadPosRankSum,Number=.,Type=Float,Description="Mann-Whitney Rank sum test for difference between in positions of variants in reads from ref and alt"> ##INFO=<ID=SC,Number=1,Type=String,Description="Genomic sequence 10 bases either side of variant position"> ##INFO=<ID=START,Number=.,Type=Integer,Description="Start position of reference call block"> ##INFO=<ID=SbPval,Number=.,Type=Float,Description="Binomial P-value for strand bias test"> ##INFO=<ID=Size,Number=.,Type=Integer,Description="Size of reference call block"> ##INFO=<ID=Source,Number=.,Type=String,Description="Was this variant suggested by Playtypus, Assembler, or from a VCF?"> ##INFO=<ID=TC,Number=1,Type=Integer,Description="Total coverage at this locus"> ##INFO=<ID=TCF,Number=1,Type=Integer,Description="Total forward strand coverage at this locus"> ##INFO=<ID=TCR,Number=1,Type=Integer,Description="Total reverse strand coverage at this locus"> ##INFO=<ID=TR,Number=A,Type=Integer,Description="Total number of reads containing this variant"> ##INFO=<ID=UNAFF_PARENTS_AF,Number=A,Type=Float,Description="Allele frequency in the UNAFF_PARENTS cohort calculated from AC and AN, in the range (0,1), in the same order as listed"> ##INFO=<ID=WE,Number=1,Type=Integer,Description="End position of calling window"> ##INFO=<ID=WS,Number=1,Type=Integer,Description="Starting position of calling window"> ##bcftools_normVersion=1.2-dirty+htslib-1.2.1 ##contig=<ID=1,length=249250621> ##contig=<ID=2,length=243199373> ##contig=<ID=3,length=198022430> ##contig=<ID=4,length=191154276> ##contig=<ID=5,length=180915260> ##contig=<ID=6,length=171115067> ##contig=<ID=7,length=159138663> ##contig=<ID=8,length=146364022> ##contig=<ID=9,length=141213431> ##contig=<ID=10,length=135534747> ##contig=<ID=11,length=135006516> ##contig=<ID=12,length=133851895> ##contig=<ID=13,length=115169878> ##contig=<ID=14,length=107349540> ##contig=<ID=15,length=102531392> ##contig=<ID=16,length=90354753> ##contig=<ID=17,length=81195210> ##contig=<ID=18,length=78077248> ##contig=<ID=19,length=59128983> ##contig=<ID=20,length=63025520> ##contig=<ID=21,length=48129895> ##contig=<ID=22,length=51304566> ##contig=<ID=MT,length=16569> ##contig=<ID=X,length=155270560> ##contig=<ID=Y,length=59373566> ##reference=/genomes/resources/genomeref/Illumina/Homo_sapiens/Ensembl/GRCh37/Sequence/WholeGenomeFasta/genome.fa #CHROM POS ID REF ALT QUAL FILTER INFO 13 32884632 . C T . . AC=1;AF=0.0000412;AN=1;CT=T|ZAR1L|ENSG00000189167|ENST00000533490|protein_coding|intron_variant|||||&T|ZAR1L|ENSG00000189167|ENST00000345108|protein_coding|intron_variant|||||&T|BRCA2|ENSG00000139618|ENST00000380152|protein_coding|upstream_gene_variant|||||&T|BRCA2|ENSG00000139618|ENST00000544455|protein_coding|upstream_gene_variant|||||&T|||||regulatory_region_variant|||||&T|||||TF_binding_site_variant|||||;PARENTS_AF=0;UNAFF_PARENTS_AF=0 13 32884636 . T A . . AC=1;AF=0.0000412;AN=1;CT=A|ZAR1L|ENSG00000189167|ENST00000533490|protein_coding|intron_variant|||||&A|ZAR1L|ENSG00000189167|ENST00000345108|protein_coding|intron_variant|||||&A|BRCA2|ENSG00000139618|ENST00000380152|protein_coding|upstream_gene_variant|||||&A|BRCA2|ENSG00000139618|ENST00000544455|protein_coding|upstream_gene_variant|||||&A|||||regulatory_region_variant|||||&A|||||TF_binding_site_variant|||||;PARENTS_AF=0.0000843;UNAFF_PARENTS_AF=0.0000899 13 32884640 . G A . . AC=2;AF=0.0000824;AN=2;CT=A|ZAR1L|ENSG00000189167|ENST00000533490|protein_coding|intron_variant|||||&A|ZAR1L|ENSG00000189167|ENST00000345108|protein_coding|intron_variant|||||&A|BRCA2|ENSG00000139618|ENST00000380152|protein_coding|upstream_gene_variant|||||&A|BRCA2|ENSG00000139618|ENST00000544455|protein_coding|upstream_gene_variant|||||&A|||||regulatory_region_variant|||||&A|||||TF_binding_site_variant|||||;PARENTS_AF=0.0000843;UNAFF_PARENTS_AF=0.0000899 13 32884647 rs142690293 T C . . AC=13;AF=0.0005355;AN=13;CT=C|ZAR1L|ENSG00000189167|ENST00000533490|protein_coding|intron_variant|||||&C|ZAR1L|ENSG00000189167|ENST00000345108|protein_coding|intron_variant|||||&C|BRCA2|ENSG00000139618|ENST00000380152|protein_coding|upstream_gene_variant|||||&C|BRCA2|ENSG00000139618|ENST00000544455|protein_coding|upstream_gene_variant|||||&C|BRCA2|ENSG00000139618|ENST00000530893|protein_coding|upstream_gene_variant|||||&C|||||regulatory_region_variant|||||&C|||||TF_binding_site_variant|||||;PARENTS_AF=0.00059;POPFREQ=GNOMAD_GENOMES_ALL:0.0029706|GNOMAD_GENOMES_EAS:0.0568603|GNOMAD_GENOMES_MALE:0.003972|GNOMAD_GENOMES_FEMALE:0.0017329|1kG_phase3_ALL:0.0087859|1kG_phase3_CHS:0.052381|1kG_phase3_JPT:0.0240385|1kG_phase3_CDX:0.0752688|1kG_phase3_KHV:0.0353535|1kG_phase3_EAS:0.0436508|1kG_phase3_CHB:0.0339806|UK10K_ALL:0.0001322|UK10K_ALSPAC:0.0002595;UNAFF_PARENTS_AF=0.0005392 13 32884653 rs206110 G T . . AC=14729;AF=0.6066809;AN=14729;CT=T|ZAR1L|ENSG00000189167|ENST00000533490|protein_coding|intron_variant|||||&T|ZAR1L|ENSG00000189167|ENST00000345108|protein_coding|intron_variant|||||&T|BRCA2|ENSG00000139618|ENST00000380152|protein_coding|upstream_gene_variant|||||&T|BRCA2|ENSG00000139618|ENST00000544455|protein_coding|upstream_gene_variant|||||&T|BRCA2|ENSG00000139618|ENST00000530893|protein_coding|upstream_gene_variant|||||&T|||||regulatory_region_variant|||||&T|||||TF_binding_site_variant|||||;PARENTS_AF=0.6065408;POPFREQ=GNOMAD_GENOMES_ALL:0.5944614|GNOMAD_GENOMES_OTH:0.5784114|GNOMAD_GENOMES_EAS:0.7806692|GNOMAD_GENOMES_AMR:0.7494034|GNOMAD_GENOMES_ASJ:0.5298013|GNOMAD_GENOMES_FIN:0.6099656|GNOMAD_GENOMES_NFE:0.5957703|GNOMAD_GENOMES_AFR:0.5403784|GNOMAD_GENOMES_MALE:0.6001878|GNOMAD_GENOMES_FEMALE:0.5873913|GONL_ALL:0.5621243|1kG_phase3_MXL:0.7578125|1kG_phase3_ALL:0.6259984|1kG_phase3_SAS:0.6237219|1kG_phase3_CLM:0.6382979|1kG_phase3_ITU:0.6029412|1kG_phase3_AFR:0.4962178|1kG_phase3_CHS:0.7761905|1kG_phase3_JPT:0.7548077|1kG_phase3_YRI:0.4907407|1kG_phase3_PJL:0.6302083|1kG_phase3_GWD:0.4336283|1kG_phase3_STU:0.6323529|1kG_phase3_GBR:0.5934066|1kG_phase3_CDX:0.7473118|1kG_phase3_KHV:0.6818182|1kG_phase3_IBS:0.682243|1kG_phase3_BEB:0.6046512|1kG_phase3_ACB:0.5416667|1kG_phase3_ESN:0.530303|1kG_phase3_LWK:0.489899|1kG_phase3_EUR:0.6182902|1kG_phase3_ASW:0.5409836|1kG_phase3_AMR:0.7262248|1kG_phase3_MSL:0.4705882|1kG_phase3_GIH:0.6456311|1kG_phase3_FIN:0.5606061|1kG_phase3_TSI:0.6401869|1kG_phase3_PUR:0.6586539|1kG_phase3_CEU:0.6060606|1kG_phase3_PEL:0.8823529|1kG_phase3_EAS:0.7371032|1kG_phase3_CHB:0.723301|MGP_ALL:0.6086142|UK10K_ALL:0.6011637|UK10K_TWINSUK_NODUP:0.606883|UK10K_ALSPAC:0.5949663|UK10K_TWINSUK:0.6076052;UNAFF_PARENTS_AF=0.6061287 13 32884664 rs532184055 C T . . AC=35;AF=0.0014416;AN=35;CT=T|ZAR1L|ENSG00000189167|ENST00000533490|protein_coding|intron_variant|||||&T|ZAR1L|ENSG00000189167|ENST00000345108|protein_coding|intron_variant|||||&T|BRCA2|ENSG00000139618|ENST00000380152|protein_coding|upstream_gene_variant|||||&T|BRCA2|ENSG00000139618|ENST00000544455|protein_coding|upstream_gene_variant|||||&T|BRCA2|ENSG00000139618|ENST00000530893|protein_coding|upstream_gene_variant|||||&T|||||regulatory_region_variant|||||&T|||||TF_binding_site_variant|||||;PARENTS_AF=0.0014329;POPFREQ=GNOMAD_GENOMES_ALL:0.000678|GNOMAD_GENOMES_AMR:0.0023866|GNOMAD_GENOMES_ASJ:0.0066225|GNOMAD_GENOMES_NFE:0.0010657|GNOMAD_GENOMES_AFR:0.0001146|GNOMAD_GENOMES_MALE:0.000701|GNOMAD_GENOMES_FEMALE:0.0006496|GONL_ALL:0.001002|1kG_phase3_ALL:0.0003994|1kG_phase3_AFR:0.0007564|1kG_phase3_GBR:0.0054945|1kG_phase3_ACB:0.0052083|1kG_phase3_EUR:0.000994|MGP_ALL:0.011236|UK10K_ALL:0.0018514|UK10K_TWINSUK_NODUP:0.001399|UK10K_ALSPAC:0.0023352|UK10K_TWINSUK:0.0013484;UNAFF_PARENTS_AF=0.0014378 13 32884665 rs774189070 C G . . AC=14;AF=0.0005767;AN=14;CT=G|ZAR1L|ENSG00000189167|ENST00000533490|protein_coding|intron_variant|||||&G|ZAR1L|ENSG00000189167|ENST00000345108|protein_coding|intron_variant|||||&G|BRCA2|ENSG00000139618|ENST00000380152|protein_coding|upstream_gene_variant|||||&G|BRCA2|ENSG00000139618|ENST00000544455|protein_coding|upstream_gene_variant|||||&G|BRCA2|ENSG00000139618|ENST00000530893|protein_coding|upstream_gene_variant|||||&G|||||regulatory_region_variant|||||&G|||||TF_binding_site_variant|||||;PARENTS_AF=0.0005057;POPFREQ=GNOMAD_GENOMES_ALL:0.0000323|GNOMAD_GENOMES_AFR:0.0001147|GNOMAD_GENOMES_MALE:0.0000584|UK10K_ALL:0.0002645|UK10K_TWINSUK_NODUP:0.0002798|UK10K_ALSPAC:0.0002595|UK10K_TWINSUK:0.0002697;UNAFF_PARENTS_AF=0.0004493 13 32884667 rs539248433 A C . . AC=4;AF=0.0001648;AN=4;CT=C|ZAR1L|ENSG00000189167|ENST00000533490|protein_coding|intron_variant|||||&C|ZAR1L|ENSG00000189167|ENST00000345108|protein_coding|intron_variant|||||&C|BRCA2|ENSG00000139618|ENST00000380152|protein_coding|upstream_gene_variant|||||&C|BRCA2|ENSG00000139618|ENST00000544455|protein_coding|upstream_gene_variant|||||&C|BRCA2|ENSG00000139618|ENST00000530893|protein_coding|upstream_gene_variant|||||&C|||||regulatory_region_variant|||||&C|||||TF_binding_site_variant|||||;PARENTS_AF=0.0000843;POPFREQ=GNOMAD_GENOMES_ALL:0.0006782|GNOMAD_GENOMES_OTH:0.0010183|GNOMAD_GENOMES_NFE:0.0000666|GNOMAD_GENOMES_AFR:0.0021774|GNOMAD_GENOMES_MALE:0.0007598|GNOMAD_GENOMES_FEMALE:0.0005775|1kG_phase3_ALL:0.0007987|1kG_phase3_AFR:0.0030257|1kG_phase3_GWD:0.0132743|1kG_phase3_MSL:0.0058824;UNAFF_PARENTS_AF=0.0000899 13 32884672 . NAGAC N . . AC=1;AF=0.0000412;AN=1;CT=|ZAR1L|ENSG00000189167|ENST00000533490|protein_coding|intron_variant|||||&|ZAR1L|ENSG00000189167|ENST00000345108|protein_coding|intron_variant|||||&|BRCA2|ENSG00000139618|ENST00000380152|protein_coding|upstream_gene_variant|||||&|BRCA2|ENSG00000139618|ENST00000544455|protein_coding|upstream_gene_variant|||||&|BRCA2|ENSG00000139618|ENST00000530893|protein_coding|upstream_gene_variant|||||&|||||regulatory_region_variant|||||&|||||TF_binding_site_variant|||||;PARENTS_AF=0.0000843;UNAFF_PARENTS_AF=0.0000899 13 32884685 . G A . . AC=1;AF=0.0000412;AN=1;CT=A|ZAR1L|ENSG00000189167|ENST00000533490|protein_coding|intron_variant|||||&A|ZAR1L|ENSG00000189167|ENST00000345108|protein_coding|intron_variant|||||&A|BRCA2|ENSG00000139618|ENST00000380152|protein_coding|upstream_gene_variant|||||&A|BRCA2|ENSG00000139618|ENST00000544455|protein_coding|upstream_gene_variant|||||&A|BRCA2|ENSG00000139618|ENST00000530893|protein_coding|upstream_gene_variant|||||&A|||||regulatory_region_variant|||||&A|||||TF_binding_site_variant|||||;PARENTS_AF=0;UNAFF_PARENTS_AF=0 |
Acknowledgements
We would like to thank Genomics England very much for their support and for trusting in OpenCGA and the rest of OpenCB Suite for this amazing release. In particular, we would like to thank Augusto Rendon, Anna Need, Carolyn Tregidgo, Frank Nankivell and Chris Odhams for their support, test and valuable feedback.
Table of Contents:
| Table of Contents | ||
|---|---|---|
|