OpenCGA implements three different command lines for different purposes, these are opencga.sh, opencga-admin.sh and opencga-analysis.sh. All of them follow the same structure, design and share many usage features:
- structure: they are organised in commands and subcommands, e.g.:
./opencga.sh <command> <subcommand> [options] - authentication: you need to be authenticated to run the command lines, only admin user can run opencga-admin.sh. Anonymous user can run opencga.sh when using public studies.
- output: all of them follow the same usage conventions for parameters and output
Architecture
Here you can find a diagram of the three command lines a brief description below:
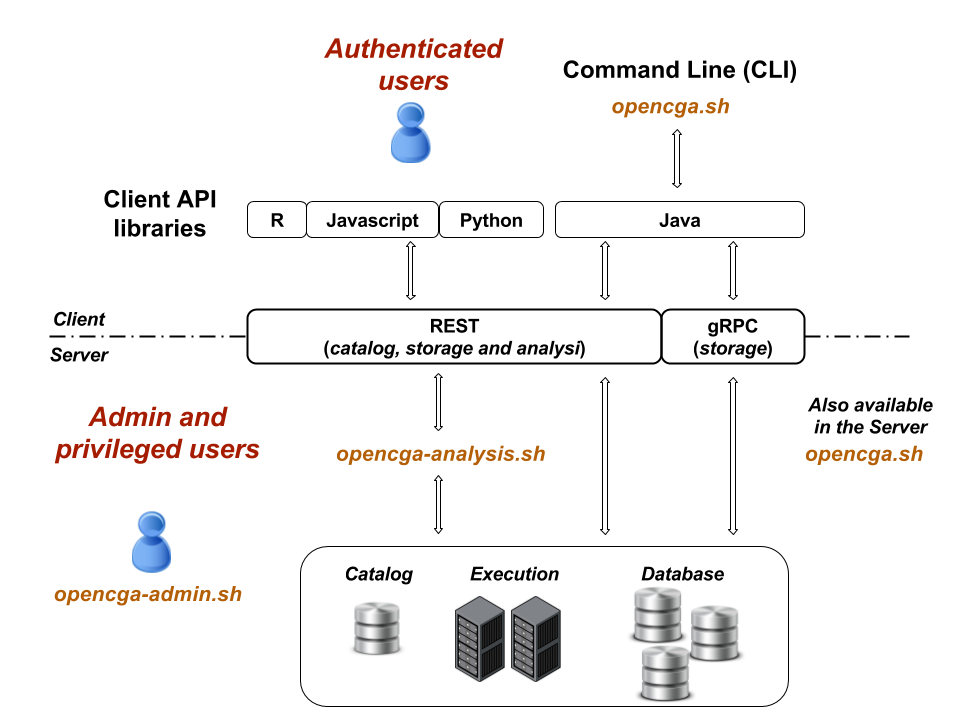
opencga.sh
This is the main command line for normal users, in fact this is the only command line that everybody should use. It implements all the functionality in more than 100 command and subcommands, for example you can login, list files, search samples or query variants. The vast majority of the subcommands run over RESTful web services so this command line can run remotely (outside of the cluster) or locallly (inside the cluster) as long as you have access to the REST server, this command line uses client-configuration.yml file. You can find more detailed information at Command Lines > opencga.sh
opencga-admin.sh
This command line requires the admin password to be executed, it allows to install catalog database and indexes, create users, query the audit, ... This does not use RESTful web services and it needs direct access to the server, so it only runs in the OpenCGA cluster and it uses configuration.yml. You can find more detailed information at Command Lines > opencga-admin.sh.
opencga-analysis.sh
This command line is used by OpenCGA system itself and nobody is expected to use it unless you are debugging and you really understand how it works. It runs in the cluster and uses configuration.yml. No more detailed information is provided at this moment.
Table of Contents: